,allowExpansion)
Language2code
How to generate code using Artificial Intelligence
Language-to-code: what is it?
The term “language-to-code” refers to artificial intelligence models that make it possible to interpret instructions in natural language and generate code that respects these instructions. While the main model is Codex, released by OpenAI, all industry leaders – including Google and Meta– have developed or planned to develop models of this kind.
These models can be applied to different use cases:

Automatic generation of documentation starting from code

Auto-completing a block of code

Translation of code from one language to another

Refactoring and automatic error correction

Automatic writing of unit tests

Automatic code generation from a description in natural language
How does a language-to-code engine work?
Language-to-code engines are implemented as transformer language models: neural networks specially trained to work on text and to understand natural language. In this respect, these models treat code as a form of language, following the left-to-right paradigm: they receive a block of text as an input (the so-called “prompt”) and return the text they identify as most suitable to complete it.
These models are often “pre-trained,” meaning the parameters that determine the result of their execution have been defined by analysing large amounts of data, such as large public source code repositories. The most advanced models currently available on the market consist of tens of billions of parameters.
The size of these models and the amount of training data used is directly proportional to their effectiveness, although at the same time it risks presenting a problem known as “overfitting.” This is when a model is so well trained that it responds almost perfectly to requests corresponding to known problems, while being far more ineffective at handling requests that deviate from its initial dataset. To avoid this problem, careful optimisation and calibration work is required on the model, to allow it the flexibility to be effective in as many different situations as possible.
Analysing language-to-code model effectiveness
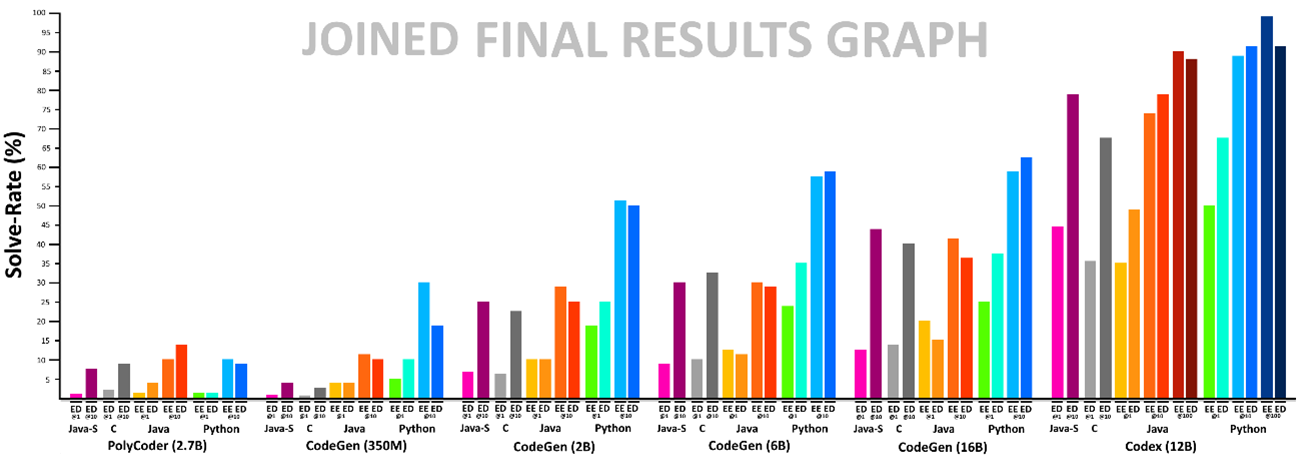
At Reply, we started testing these models in order to explore the different application use cases and to evaluate their relative effectiveness. Specifically, we have defined an approach that makes it possible to analyse objectively the effectiveness of the various language-to-code models available on the market. This procedure is based on HumanEval, a set of programming problems designed to cover a wide spectrum of cases.
The test consists of subjecting the various problems of the HumanEval set to the models and executing the generated code, verifying how correct the output is. In fact, this test is performed several times, until it returns a correct result. The percentage of tests passed corresponds to the index of the model’s effectiveness.
We have also developed a variant of this test which, in addition to the problem text, also provides some examples of the expected results. This variant tends to favour models that effectively “understand” the meaning of the requests, over those that associate the request with a known problem, therefore taking advantage of overfitting.
This approach has been developed so that it can easily be extended and applied to different programming languages and models, in turn making it possible to effortlessly repeat the tests and replicate the results on new models that will emerge in the near future. Following the execution of the tests, Codex ranked first among the different models analysed by Reply, surpassing even larger models and thus emphasising the effective calibration process to which it has been subjected.
Execution tests and error correction
On the basis of the development and execution of the effectiveness tests, we reached the definition of a procedure to improve the correctness of the code generation processes from natural language, associating to the description a set of 'acceptance conditions' that allow the correctness of the result obtained to be verified. The code generation is therefore executed several times, until the correctness tests return a positive outcome.
By adopting this approach, it is thus possible to discard incorrect output and ensure the correctness of the procedures automatically, without requiring manual checks. At Reply, we are actively working on this methodology, in order to support our customers in testing their specific language-to-code use cases.