)
Génération dynamique de DAG
Focus sur Airflow et Jinja
Introduction
Dans cet article, vous apprendrez à générer dynamiquement des DAGs dans Apache Airflow à partir d'un template Jinja. Ce template contient la définition Python d'une chaîne commune de tâches et un paramétrage de la configuration à passer dans votre chaîne Jinja. Le résultat sera la construction de DAGs pour différents contextes basés sur cette chaîne commune.
Apache Airflow est l'un des outils de gestion de tâches les plus couramment utilisés. Il fournit un cadre flexible et extensible pour la gestion, la programmation et la surveillance des pipelines de données. Airflow permet aux utilisateurs de définir, planifier et exécuter des flux de travail sous forme de graphes acycliques dirigés (DAG). Les DAGs peuvent être vus comme une collection de tâches avec des dépendances définies entre elles. Chaque tâche dans Airflow est définie comme un opérateur qui est une abstraction d'une instruction spécifique. Par exemple, un PythonOperator exécutera une fonction Python.
Le pipeline de notre centre de données se compose de trois tâches Glue :

1. Landing job

2. Raw job

3. Curated job
Lecture des données à partir de différentes sources (base de données relationnelle, fichiers CSV à partir de serveurs SFTP...) et écriture des données dans un bucket S3 dans leur format original (dans le cas des bases de données, nous écrivons dans un format de type parquet).
Lecture des données depuis le landing bucket, vérification de la qualité des données et écriture des données avec partitionnement dans un format parquet unifié dans un bucket S3.
Lire les données à partir du bucket Raw et les écrire dans un format Apache Iceberg.
En outre, nous devons exécuter cette opération pour plusieurs pays, chaque pays ayant ses propres sources spécifiques. Nous voulions néanmoins disposer d'une vue centralisée pour surveiller l'exécution de la collecte. Nous avons donc opté pour Apache Airflow dans un compte AWS central. Mais nous devions trouver un moyen de créer des DAGs de manière dynamique (en changeant certains paramètres dans la définition du DAG pour chaque domaine) et d'exécuter le même pipeline (Landing, Raw et Curated) pour ce domaine. Ayant déjà travaillé avec Jinja dans la génération de pages web, la génération SQL et même dans Airflow, nous avons voulu essayer de tirer parti de cette technologie pour créer dynamiquement des fichiers Python qui contiennent chacun le code de collecte du pipeline de données pour chaque domaine dans chaque pays avec leurs paramètres spécifiques.
Jinja est un moteur de templating rapide, expressif et extensible pour Python. Jinja est largement utilisé pour générer dynamiquement du HTML, du XML et d'autres langages de balisage. Dans notre cas d'utilisation, nous voulions l'utiliser pour développer des DAG de manière dynamique. Nos DAGs auront la même structure et consisteront en trois tâches principales :
1ère tâche : Exécuter le job Glue de la landing zone avec les paramètres du pays et du domaine (liste des tables à récupérer et des identifiants).
2ème tâche : Exécuter le job Glue raw avec les paramètres du pays et du domaine (liste des tables à traiter)
3ème tâche : Exécuter la tâche Glue curated avec les paramètres du pays et du domaine (liste des tables à traiter)
Pour ce faire, nous avons créé un modèle Jinja unique contenant la définition d'un DAG avec les trois tâches décrites exécutées en chaîne. Chacune des tâches est un PythonOperator qui appelle une fonction Python exécutant un job Glue. Cette fonction prend comme paramètres :
job_name : le nom de la tâche Glue
job_arguments : Un dictionnaire de paramètres à passer aux jobs Glue (liste des tables, nom du secret, etc.).
Pour chacune des trois tables, nous remplaçons le nom du job et les valeurs des arguments du job par un modèle Jinja. Nous faisons de même pour l'ID du DAG et le scheduling que nous paramétrons avec des valeurs Jinja.
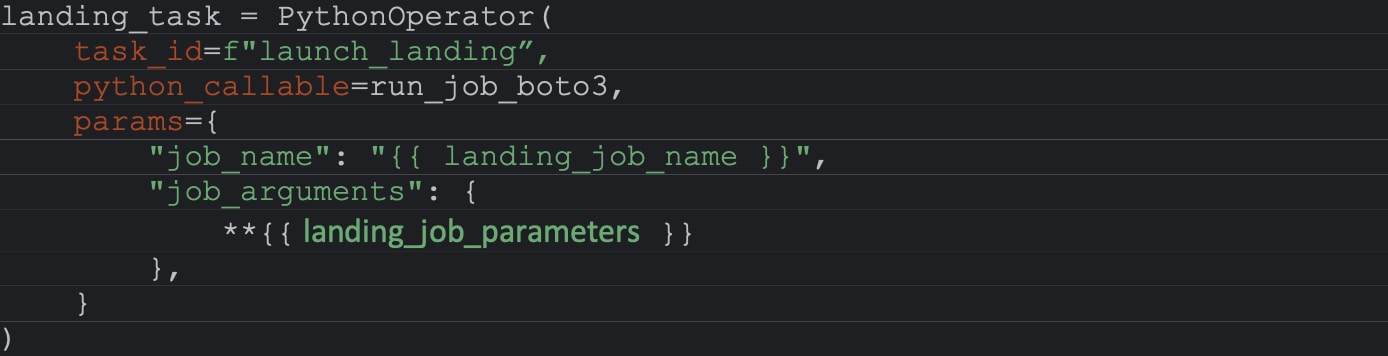
Génération Dynamique de DAGs Airflow avec Jinja et AWS Glue
Jinja est un moteur de templating rapide, expressif et extensible pour Python. Jinja est largement utilisé pour générer dynamiquement du HTML, du XML et d'autres langages de balisage. Dans notre cas d'utilisation, nous voulions l'utiliser pour développer des DAG de manière dynamique. Nos DAGs auront la même structure et consisteront en trois tâches principales :
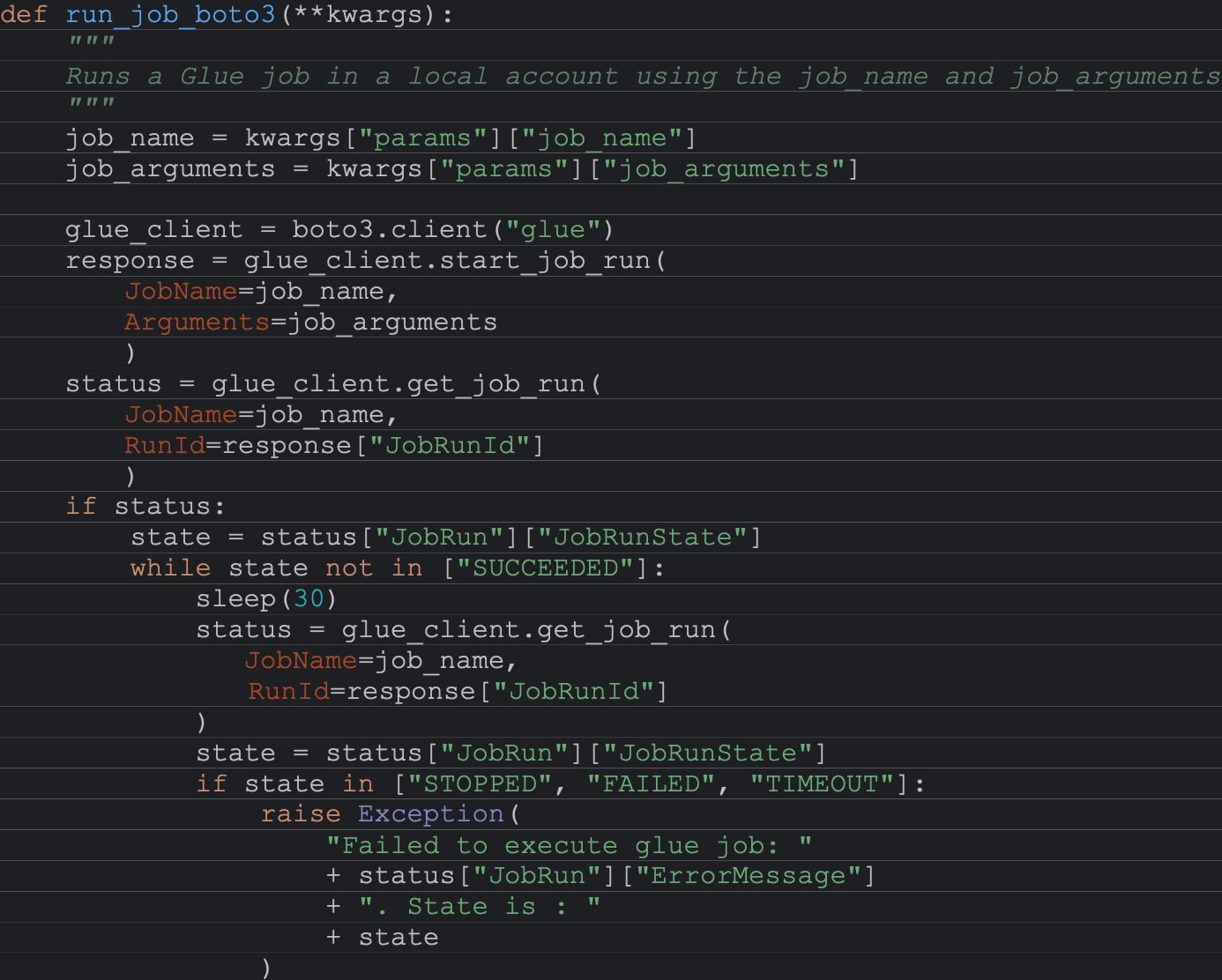
La fonction run_job_boto3
La fonction run_job_boto3 est une fonction Python qui prend des kwargs (contenant un nom de job et un répertoire de paramètres) et exécute un job Glue en utilisant le nom spécifique ainsi que la liste des paramètres.
Nous avons donc défini le modèle de notre exécution. Nous avions besoin de définir quelque chose qui crée pour chaque pays et domaine un fichier Python avec les valeurs correspondantes pour l'ID DAG, le calendrier, le nom du job Glue et les paramètres spécifiques en fonction du pays et du domaine. Afin de créer différents DAG, nous créons ce que nous appelons un DAG maître qui lit la configuration de chaque domaine dans chaque pays.
Ces fichiers de configuration sont des fichiers YAML qui contiennent pour chaque pays son planning, le nom des credentials dans AWS Secrets Manager, le type de connecteur dans landing (SQLServer, Oracle, SFTP) et la liste des tables à passer au job Glue. L'étape suivante consiste à créer pour chaque pays, sur la base de ces paramètres et en utilisant le modèle, un fichier Python qui exécute le flux de travail pour le pays et le domaine.
1ère étape
Lecture du fichier YAML et préparation des paramètres pour l'étape suivante

2ème étape
Création du fichier Python
Conclusion
Pour conclure, ce que nous avons présenté ici est un moyen parmi d'autres de générer dynamiquement des DAGs qui ont une chaîne d'exécution similaire. Il peut être utilisé chaque fois que vous devez exécuter la même structure de workflows mais avec des modifications comme par exemple l'utilisation de paramètres spécifiques pour chaque groupe.
Data Reply

Data Reply est la société du groupe Reply offrant une large gamme de services d'analyse avancée et de données alimentées par l'IA. Nous opérons dans différentes industries et fonctions commerciales, en travaillant directement avec des professionnels de niveau exécutif et des directeurs généraux leur permettant d'obtenir des résultats significatifs grâce à l'utilisation efficace des données.