
,allowExpansion)
Empower data scientists, marketing managers, and IT decision-makers with a User and Entity Behavior Analytics (UEBA) application, facilitating targeted marketing campaigns fueled by real-time user behavior insights.
Data Reply IT actively participates in the Build with Confluent initiative. Through validation of our streaming-based use cases with Confluent, we ensure that our Confluent-powered service offerings leverage the capabilities of the leading data streaming platform to their fullest potential. This validation process, conducted by Confluent's experts, guarantees the technical effectiveness of our services.

In our business context, we leverage a data-driven approach, utilizing advanced unsupervised machine learning techniques like K-means clustering to extract valuable insights from transactional data. Our primary objective is to enhance real-time reporting and analytics capabilities by understanding user behavior through effective labelling strategies and streamlining development processes for increased efficiency and agility.

K-means clustering is an unsupervised machine learning algorithm utilized to group data into homogeneous clusters. It divides a dataset into K clusters, with each cluster represented by a centroid, the average point of all points in the cluster. This method is widely applicable across various fields for its effectiveness in data grouping and analysis. We opt for unsupervised machine learning since it does not require a training dataset, and the data can be processed as it flows in.

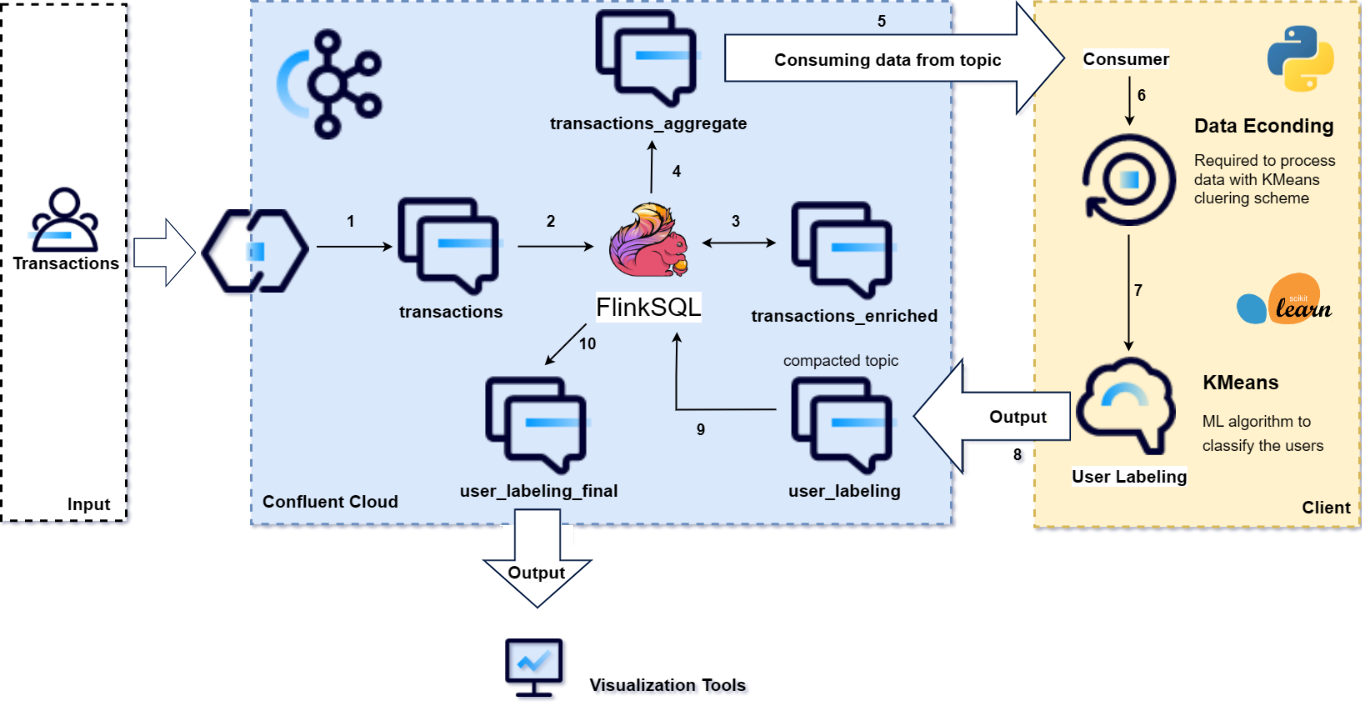
Our streaming pipeline begins with transactional data input received within the 'transactions' topic. Leveraging FlinkSQL, we enrich the data by adding transaction entity information, facilitating meaningful user labelling. The enriched data is then aggregated by the user id using FlinkSQL aggregation functions and sent to the topic representing the transactions aggregated. This aggregated data is consumed by a Kafka consumer in a Python script, processed, and prepared for the K-means clustering algorithm. After clustering, the results are written to a topic with the most updated compacted data for visualization using any data visualization tool.
Curious for more information? Click on the GitHub link to learn more about the hands-on project
Confluent
)
Confluent is the data streaming platform that is pioneering a fundamentally new category of data infrastructure that sets data in motion. Confluent's cloud-native offering is the foundational platform for data in motion – designed to be the intelligent connective tissue enabling real-time data, from multiple sources, to constantly stream across the organization. With Confluent, organizations can meet the new business imperative of delivering rich, digital front-end customer experiences and transitioning to sophisticated, real-time, software-driven backend operations.