)
Optimising AI Efficiency with Amazon Bedrock
Introduction
With the advent of Large Language Models, great complexity and utility have emerged. Approaches such as Retrieval Augmented Generation and Fine-tuning aid in extracting the benefits of this powerful technology. These methodologies have given rise to a new field of AI known as Generative AI, specifically focused on creating new material, whether it be text generation or media, via these large models. There are numerous business applications for Generative AI. One can appreciate how these large language models can be used as a reasoning engine to complete some of the more laborious tasks in a business, thus providing time and financial benefits.
Unfortunately, this utility tends to be wrapped around rather complicated libraries. Therefore, there is a need for a more streamlined, user-friendly approach towards the development and deployment of LLM-powered applications. Bedrock is AWS's solution to this challenge; it offers a simple API capable of interacting with a variety of different foundational models AWS offers. With LLMs providing immense latitude in business applications, a position AWS seems to support given their recent $4bn investment into Anthropic, Bedrock certainly fills the void by providing a structured and easy approach to developing and deploying these applications.
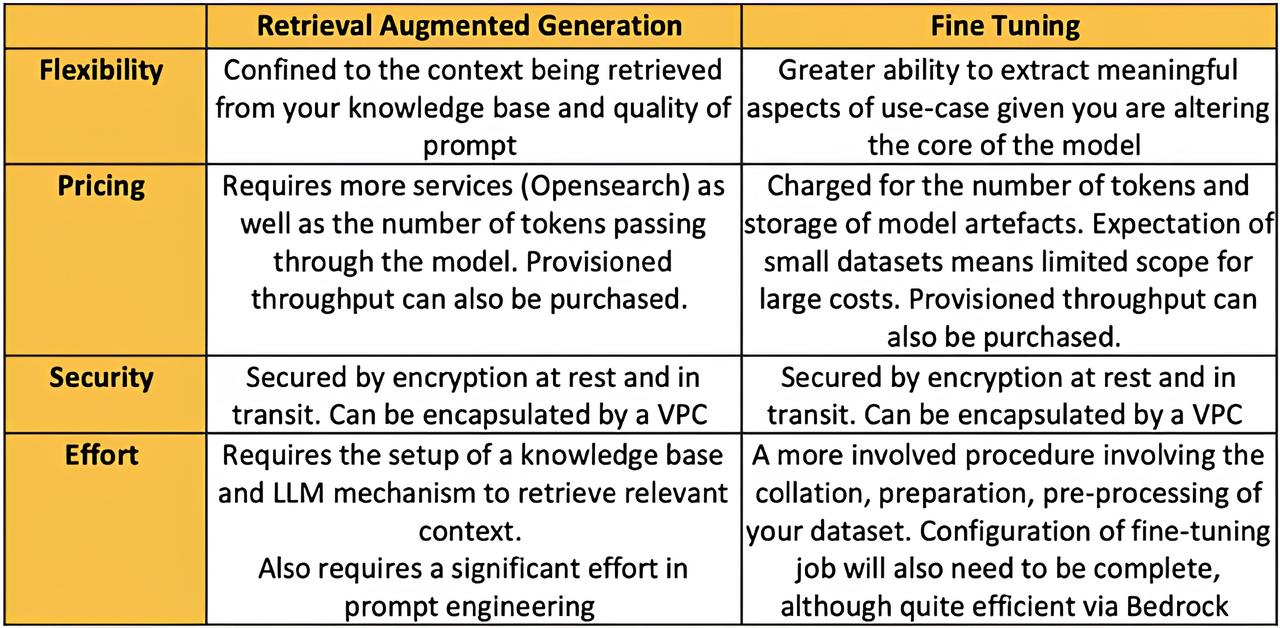
Optimising AI with AWS Bedrock: RAG vs Fine-Tuning
AWS provide a diverse array of what they refer to as foundational models (FM). These are large models which are not limited to the language kind and are therefore able to serve varied business use-cases. They are sourced from a variety of vendors which includes A121, Anthropic, Cohere and Stability AI. It’s worth mentioning that some of these models are packaged with their own embedding engine, namely Cohere and AWS’s proprietary model, Titan.
Perhaps a more pertinent feature for customers is the pricing structure of Bedrock. Given the serverless nature of the offering, it provides limited scope for charging customers. The service provides significant cost savings through the purchasing of provisioned throughput when taking your model to production, that is, computational units which allow for the consistent invocation of your model endpoint.
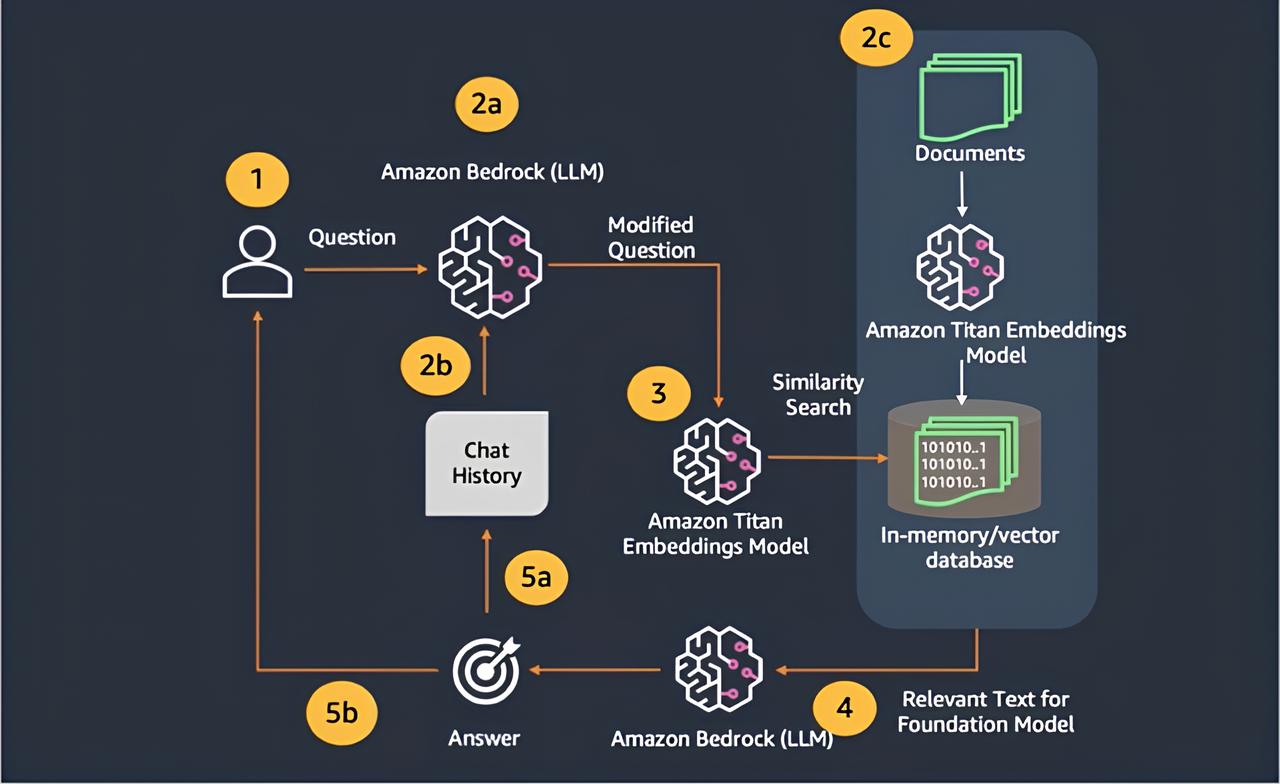
For us to appreciate the power of Bedrock, we must first acknowledge the more common use cases pertaining to generative AI applications. In our experience, the vast majority of applications require a knowledge base capable of bootstrapping our generative AI application which the relevant context to facilitate a particular task.
There are two methods capable of facilitating this, one being a direct approach whilst the other indirect. The initial approach is referred to as Retrieval Augmented Generation and pertains to the injection of contextual information within a prompt sent to an LLM. This context is typically retrieved from a knowledge base containing all the data that the application could require to answer questions.
The second method is far more comprehensive and as such, more expensive. Fine tuning is the process of modifying the underlying weights of the model by way of retraining these weights on a new dataset tuned on your particular use case. Within the scope of LLM’s it seems rather intuitive that this can incur a rather excessive time and financial cost which makes it unfeasible to pursue this avenue for most companies. Consequently, we observe that most companies who employ generative AI favour the initial RAG approach and indeed it seems to be effective.
Embeddings, more specifically vector embeddings, are a means to transform textual information into a numeric format that computers can comprehend. Traditionally, this would be achieved by way of identifying overlapping n-grams within two different sentences. It’s worth mentioning at this stage that from a high-level viewpoint, an n-gram is a continuous sequence of characters or words, and in this case, the word format is more germane. For instance, the sentence ‘the dog leaped over the fence’ and ‘that animal just jumped over the gate’ contain very few overlapping n-grams given that the majority of words present in these two sentences are different. Alternatively, a human reading the sentence would deduce that the two sentences appear to be semantically similar, in that they both refer to an animal jumping over an object.
What word embeddings aim to do is to encapsulate all of this semantic meaning within vectors, such that sentences which include distinct words yet refer to the same thing, are appreciated as possessing similar semantic meaning. This is a more robust mechanism for extracting meaning from textual data and thus, bootstraps an LLM with the ability to appreciate context, given that meaning is a pre-requisite for context.
The best practice within the scope of RAG is to effectively render your documents into various chunks, which can then be transformed into vector representations of these documents and subsequently, stored within a vector store. AWS offers a variety of different vector stores with the most popular being that which is offered via the OpenSearch Service. Now, if the primary use case was to simply design a product capable of the rapid retrieval of the most relevant documents with respect to a query, then this would all be all we would need. However, another area of complexity within this field is that of agents, another area which the Bedrock service aims to incorporate.
Agents are effectively autonomous actors who are capable of designing their own prompts with respect to a specific task you have allowed it to complete. More concretely, these agents are provided access to a customer’s corporate eco-system by way of API’s, and are therefore capable of completing more laborious tasks for you. This is made possible by virtue of integrating the aforementioned knowledge base within your agent, such that it is able to produce richer prompts amplified by company-specific information. Bedrock once again reveals its ability to abstract away the complexities of building such systems by providing these agents in a serverless manner, that is, eradicating the need to worry about infrastructure. A major facilitator of this serverless approach is the ability for Bedrock to allow customers to insert their business logic within Lambda’s. It is within these Lambda’s where our RAG approach re-appears, that is to say, these Lambda’s serve as a middle-man for the LLM, retrieving the company-specific information to augment the LLM’s ability to complete the business logic, also within the Lambda.
A rather under-appreciated feature of the agent's offering is the ability for these agents to write their own prompts, given an initial description which acts as a guiding principle. Anyone who has had some exposure to the more popular LLM development orchestration packages will appreciate how time-consuming engineering a prompt can be. More compounding is the area of tuning the prompt to achieve reproducible results. Unfortunately, some business-specific tasks may be more specific than others. In particular, there exist certain tasks which may be so niche to the point to which bootstrapping context by way of RAG, in the interest of completing a task, may not suffice.
Jobs which have failed to produce adequate results by way of RAG or, require a greater more nuanced insight into the dynamics of a business to produce valid results, will require a more refined treatment via fine-tuning. This is the process through which the weights inherent to a foundational model are tuned to reflect the specific task a customer hopes to achieve. Bedrock provides a simple API to invoke these jobs along with the promise that it creates a copy of the FM being tuned within a customer’s own environment (VPC), thus offering an additional layer of privacy and ensuring ownership. Labelled datasets to be employed during the fine-tuning procedure are uploaded to s3 and then pointed to during the invocation of the fine-tuning job. A comprehensive set of metrics is also logged to the output s3 location chosen.
Whilst some may view the collation of data to curate a dataset to utilise during the fine-tuning procedure as an impediment, it's crucial to remember that these are Large Language models and therefore already maintain a strong grounding in understanding natural language. One of the more beneficial aspects of this is that it places a limitation on the quantity of training samples we need to fine-tune a model. In fact, these models require somewhere in the region of 1-100 training samples as they seem to perform better when not overburdened with large fine-tuning datasets. Indeed, a large dataset can lead to a phenomenon known as catastrophic forgetting, a process through which the LLM begins to forget all of the rich semantic information it achieved during the pre-training phase.
A mention on pricing is now long overdue, after all, we are effectively talking about performing computations on a large model hosted on the cloud. In fact, this is a critical point in determining which route to take, RAG or fine-tuning. The final hurdle a customer must overcome, given their use-case has fulfilled all the previously mentioned fine-tuning requirements, is whether they are willing to spend extra on the financial burden of fine-tuning. The pricing structure for tuning foundational models is actually not all that complicated; you simply pay per token and for the storage of your training dataset on S3. AWS explicitly states that the formula number of tokens in training data corpus x number of epochs added to the cost for storage will provide you with the total cost for customizing a FM.
A key component is the number of epochs, that is, the number of times your tuning job has gone over the entirety of your training data. This is a hyper-parameter that customers must decide upon. This decision can be aided with the rich training metrics outputted upon the completion of a fine-tuning job, and will involve the observation of how many epochs it has taken for the training loss to converge. Intuitively, a lower epoch will result in lower costs to be incurred during the fine-tuning exercise, given that pricing is measured in number of tokens passed to the model. However, customers must be careful to strike a balance between pricing and achieving model convergence. Indeed, a tuning job sacrificing model convergence for pricing purposes may be indicative of a use case which should be pursued via a RAG approach.
Security is a major topic in the realm of generative AI and with more mainstream businesses adopting gen-ai as a viable mode of delivering business excellence, it becomes crucial to account for the security of customers’ data. One of the most prominent criticisms, or rather worries of customers, is that their data will be stored for the purposes of fine-tuning these large models. A mechanism to protect against this is the implementation of encryption at rest and in transit, that is to say, customers can encrypt their data using keys either managed by AWS or yourself. The service also provides the capability to encapsulate your models within your own VPC, a course of action which will see to it that customer data can be shielded away from the public internet. A secondary mode of ensuring security is the architectural element of placing these models in individual escrow accounts, more specifically, each model is placed in an AWS-managed account to eradicate the possibility of model providers scraping your data for their own use cases.
Moreover, AWS adds two additional measures of privacy. The first involves the copying of the foundational model to customers’ own private environment during fine-tuning, such that customers retain ownership and privacy regarding the customizations conducted on the foundational model. The second measure involves the capability of limiting data traffic to private IP space, that is, all data transmitted to and from the FM will never travel via the open internet. This guardrail prevents the possibility of data being stolen or accessible by third parties, given that the tunnel orchestrated by AWS’ PrivateLink will always limit the transmission of data to within private IP space.
For your public-facing applications, Bedrock also provides the ability to seamlessly monitor the inputs to your model and identify potentially toxic messages. Bedrock conducts specialised machine learning-powered monitoring and classification under the hood to identify potentially harmful messages and, ensure that your services are not being abused. An integration between Bedrock and other existing services such as Verified Permissions will also allow for fine-grained control into who can access certain aspects of your application. A use case we have found this to be exceptionally imperative in is protecting certain aspects of your knowledge base, such that, only specific users can access particular aspects of your knowledge base.
This is a methodology which aims to force the LLM to generate semantically meaningful content germane to the particular use case at hand. We find that this methodology is best suited for use cases which do not require an appreciation of more nuanced aspects such as a customer’s brand and company specific jargon. In true Bedrock fashion, the service streamlines the procedure of collation of information from customers’ private data sources. Given the embedding engine offerings mentioned previously, it makes it simpler to ingest these documents and convert them to a representation these foundational models can work with, that is, vector embeddings.
A New Frontier
The pursuit of RAG or fine-tuning is an important decision within the context of LLM-powered applications, albeit quite nuanced. The consensus seems to be that in its current incarnation, Bedrock appears to be optimised for both methodologies. With the easy-to-use console interface and API available, the only potential obstacle is to identify what to employ Bedrock for, whether it be an adoption of a RAG-based approach or a more specialised use case demanding fine-tuning.