,allowExpansion)
Digital platform
A new approach to move from Informatization to Digitalization of manufacturing process
Most manufacturer have succeeded in informatizing their production processes. However, they have failed in taking advantage of information coming from systems. Let’s discover a new approach called Digital Platform to leverage all information that the manufacturer informatization is providing.

Informatization

Business intelligence
For the last forty years manufacturer companies have been transitioning from manual operations to an informatized production system. Major parts of their operations are now controlled or supported by computers. Nowadays manufacturer manages inventories, bills of materials, defects, parts tracking and assembly lines using several dedicated applications. This informatization has greatly helped improve productivity and reduced costs and thus improving operations margins. Noways running a production process without computers would by almost impossible.
Leveraging this informatization manufacturer are now trying to move to new opportunities: collecting and analyzing lots of data about the manufacturing process there are lesson to be learned and improvement to be made.
While a complete list of all possible improvement would be difficult and definitely industry specific, there are anyways some that should have a very broad applicability. Such as:
Analyzing and pin pointing quality defects root causes
Managing and optimizing workforce skills, characteristics and deployment
Managing and anticipating material availability and distribution problems
In the manufacturer environment there are several not integrated applications and most of them do not talk directly to each other. In addition, this applications have a different data model. The business intelligence approach tries to solve these challenges building huge data extractor from each application. Then it tries to build a centralized and omni-comprehensive data model, with all the possible data types. All application data must then fit this centralized data model. This approach has failed more times than has succeeded mostly for the following reasons:
Extracting data from applications is a time consuming development task and it is difficult to maintain overtime because any change to the application or to the centralized data model implies a change of data extractors
The centralized data storage quickly tends to become very huge in order to accommodate all the different data types
Maintaining a central defined data catalog does not allow for quickly evolving applications:
When an application need to define a new data type the central data model should be checked in order to see whether the same information have already been classified
If it’s not already been classified a classification process should start
This process should understand the data and all the data relationships with all other data types in the enterprise
This process is time consuming and this is in conflict with the business time where solutions are almost always needed yesterday
For the above reasons the centralized catalog is either directly abandoned over time or the data is just added without been properly classified. In both cases the central data for any application no longer exist.
Digital Platform Approach
Digital Platform aim to provide a software architecture where applications may thrive. A modular approach that can be flexible, standardized and economically advantageous. These goal may be reached moving commonly used services out of the applications into a platform that supports the applications. Services such as authentication, authorization, messaging, communication (Hardware Communication), monitoring, deployment are delegated by the application to the platform.
In this way the applications may focus more on their core functionalities and less on infrastructure common services. The platform provide a toolbox to make applications:
Scalable
Reliable
Observable
Maintenable.
The logical architecture of a Digital Manufacturing platform is presented in the picture:
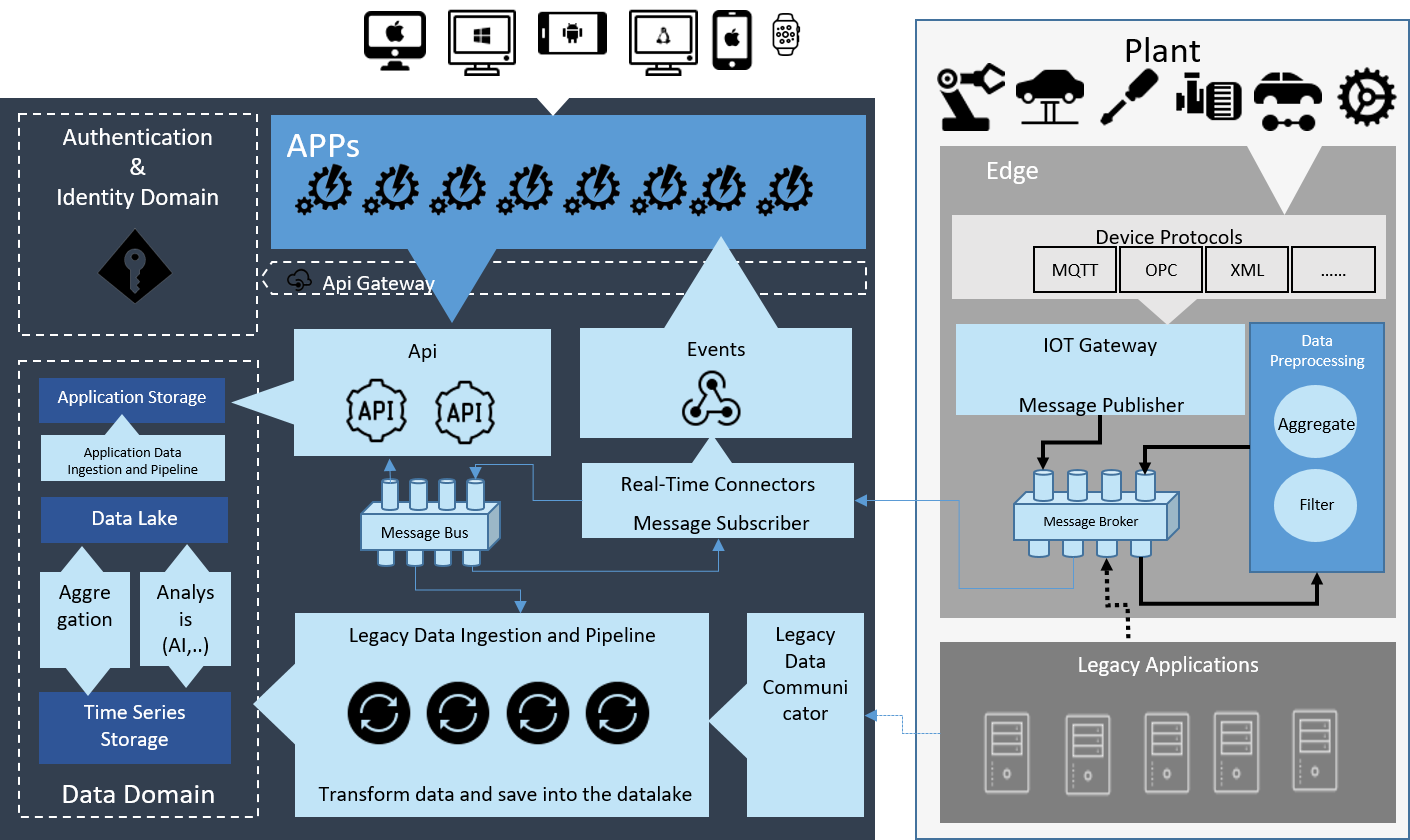
Do you want to collect, store, process and deliver data in order to extract business value from them? Find out why the digital platform approach is the right choice through a scenario evaluation. A simple comparison between the lifetime of an application built upon informatization and business intelligence versus a digital platform approach was analyzed.